
Basics of Machine Learning
Each machine learning model that you make will recognize different categories. For example, you could create an image recognition model to determine whether a picture shows either you or your cat. To create a model, you will use data that are labeled with the correct categories; in our example, the data might be pictures of you or your cat labeled “person” or “cat.” This data is called the training data, and each piece of data is a sample. This type of machine learning, where the training data are labeled with the correct categories, is called supervised learning. There are also algorithms that can determine the categories for themselves (unsupervised learning), but we won’t be using those here.
The training data is used to train the machine learning model. Training is a mathematical process that happens behind the scenes with the Google Teachable Machine. Basically, the computer is trying to find equations that use features in a sample to predict the category it belongs to. For example, if your cat has orange stripes, the model might use color to distinguish between you and the cat.
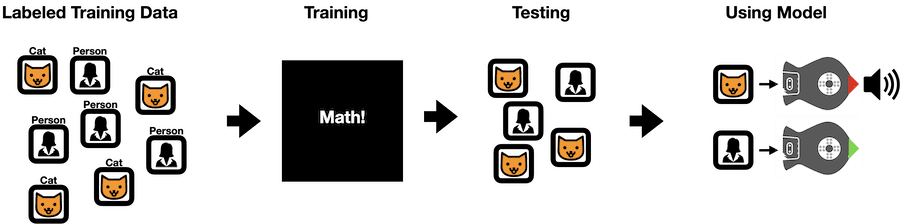
Once you have trained a machine learning model, it is important to test it to see if it behaves as you expect. Can it consistently tell the difference between you and your cat? If not, you may need to train it again with more training data. Real-world machine learning algorithms are trained using an incredible amount of data, though these activities will use small data sets.
Finally, once you are happy with your model, you are ready to use it to do something. In these examples, we will be using each model to control the Finch robot. For example, you might use your Finch to protect your desk from your cat. If the machine learning model detects the cat, the Finch will turn its beak red and sound an alarm! If it detects you, the beak will turn green.
One thing to keep in mind throughout these activities is that a machine learning model is only as good as the data that trained it. As you create models, test them with data that is both similar to and different from your training data and notice what happens.